Wenn Sie verstehen möchten, wie Suchmaschinen funktionieren, müssen Sie sich mit zwei zentralen Begriffen beschäftigen: Crawling und Indexierung. Diese Prozesse entscheiden darüber, ob und wie Ihre Webseite überhaupt in den Suchergebnissen erscheint.
Ohne dieses Grundwissen bleibt Suchmaschinenoptimierung reines Rätselraten.
In diesem Blog erklären wir Schritt für Schritt, wie Google & Co. Inhalte erfassen, bewerten und in den Index aufnehmen – und wie Sie das gezielt für Ihre Sichtbarkeit nutzen können.
Was ein Crawler ist und wie er arbeitet
Suchmaschinen wie Google nutzen sogenannte Crawler – auch bekannt als Webcrawler oder Googlebot. Diese Programme durchsuchen das Internet automatisiert nach neuen und aktualisierten Inhalten. Dabei folgen sie Links, speichern Informationen und bauen so den sogenannten Suchindex auf.
Ein Crawler:
- durchsucht HTML-Seiten, PDFs, Bilder, E-Mail-Adressen und mehr
- startet regelmäßig neue Durchläufe basierend auf alten Daten
- prüft, ob Inhalte neu, verändert oder gelöscht wurden
Damit eine Seite zuverlässig gefunden wird, muss sie vom Crawler erreichbar sein. Versteckte Inhalte, zu tiefe Seitenstrukturen oder blockierte Links behindern das Crawling.
Warum der Index der Suchmaschine so wichtig ist
Google durchsucht nicht live das Internet. Stattdessen wird jede Suchanfrage im internen Index verarbeitet – also in einer riesigen Datenbank mit Milliarden gespeicherten Seiten.
Ein Vergleich:
Google ist wie ein Restaurant. Der Gast (Nutzer) bestellt ein Gericht (Suchanfrage). Damit die Küche nicht erst einkaufen muss, sind alle Zutaten (Webseiten) längst vorbereitet. Wer im Index fehlt, wird nicht „serviert“.
Für SEO bedeutet das:
- Nur indexierte Seiten können ranken
- Der Index wird ständig aktualisiert
- Keywords bestimmen, welche Seiten zu welcher Anfrage passen
Google Search Console richtig nutzen
Die Google Search Console ist das zentrale Werkzeug für Seitenbetreiber. Sie zeigt, ob und wann der Googlebot Ihre Seiten besucht hat – und ob sie indexiert sind.
Wichtige Funktionen:
- Crawling manuell anstoßen (z. B. bei neuen Seiten)
- Indexierungsstatus einzelner URLs prüfen
- Fehler wie Serverprobleme oder blockierte Inhalte erkennen
Außerdem lässt sich über die Datei robots.txt das Crawling einschränken. Wichtig: Wer Seiten aus dem Index fernhalten will, sollte zusätzlich noindex setzen.
Was das Crawl-Budget ist und wie Sie es richtig nutzen
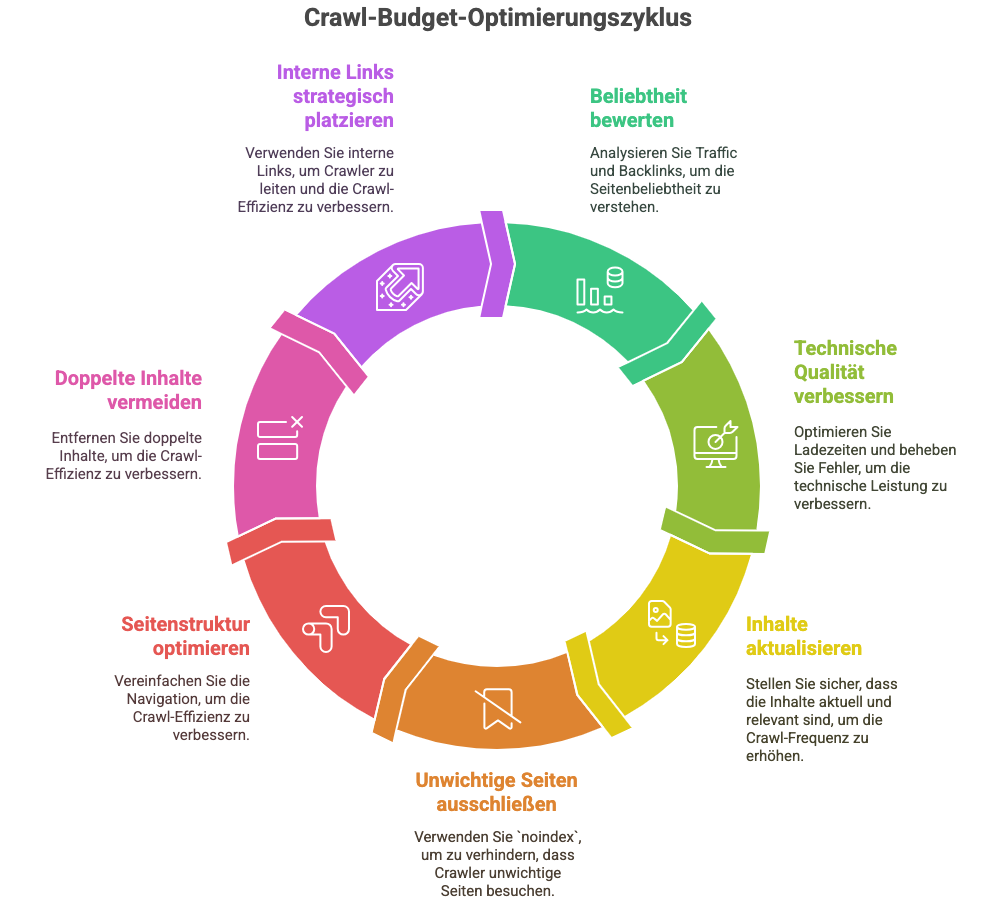
Jede Webseite bekommt ein individuelles „Crawl-Budget“ – also ein Limit, wie oft und wie tief der Bot auf Ihrer Seite lesen darf.
Das Crawl-Budget hängt u. a. ab von:
- der Beliebtheit Ihrer Seite (Traffic, Backlinks)
- technischer Qualität (z. B. Ladezeit, Fehler)
- Aktualität der Inhalte
Was Sie tun können:
- Unwichtige Seiten auf
noindexsetzen - Flache Seitenstruktur wählen (nicht mehr als 3–4 Klicks zur Zielseite)
- Duplicate Content vermeiden
- Interne Links sinnvoll platzieren
Ein gutes Crawling sorgt für aktuelle Rankings und bessere Auffindbarkeit.
Wie Sie prüfen, ob Ihre Seite indexiert ist
Es gibt zwei einfache Methoden, um zu testen, ob eine URL im Google-Index ist:
- site-Abfrage in Google:
site:ihre-domain.de/seite→ zeigt, ob die Seite gelistet ist - URL-Prüftool in der Search Console: Dort erhalten Sie technische Details zur Indexierung, Crawling-Verlauf und ggf. Fehlermeldungen.
Nicht vergessen: Seiten können auch wieder aus dem Index entfernt werden – z. B. durch Serverfehler, mangelhafte Inhalte oder Verstöße gegen Googles Richtlinien.
Fazit
Wer online gefunden werden möchte, muss verstehen, wie Suchmaschinen funktionieren. Nur Seiten, die sauber gecrawlt und korrekt indexiert sind, haben überhaupt eine Chance auf gute Rankings.
Mit den richtigen technischen Grundlagen, einer klaren Struktur und dem gezielten Einsatz der Google Search Console legen Sie den Grundstein für mehr Sichtbarkeit.
Es lohnt sich, in saubere SEO-Basics zu investieren – denn ohne Indexierung gibt es keine Reichweite.